End-to-End Process
- Objective Setting
- Data Curation
- Data Inspection
- Data Preparation
- Data Analysis
- Evaluation
- Deployment
Data Preprocessing
- 80%의 시간과 노력이 이 단계에서 필요합니다.
- 중요한 4 단계가 있습니다. (각 단계는 반드시 연속적일 필요는 없습니다.)
- 몇 개는 소프트웨어 도구를 사용하는 전문가가 필요합니다.
- 몇 개는 기초 통계의 이해가 필요합니다.
Data Preprocessing 종류
- Data Restructuring
- Horizontal Decomposition
- Vertical Decomposition
- Table Merge
- Data Value Changes
- Cleaning dirty data
- Text preprocessing
- Data discretization
- Data normalization/standardization
- Encoding for data mining algorithms
- Feature Engineering
- Derive New Features from Existing Ones
- Converting Values to New Features
- Data Reduction
Data Restructuring
- 데이터 분석이나 머신러닝 알고리즘 적용 전에 데이터셋을 적절히 조직화하고 최적화하는 과정
- 주요 재구조화 기법은 다음과 같습니다.
- 수평 분해(Horizontal Decomposition)
- 하나의 테이블을 두 개 이상의 테이블로 분할하는 과정으로, 모든 열은 유지하되 행을 조건에 따라 나눕니다.
- 예를 들어, 나이가 30 미만인 사람들과 30 이상인 사람들로 데이터를 분할할 수 있습니다.
- Data Reduction에서 사용하는 기술과 유사하다.
- 수직 분해(Vertical Decomposition)
- 하나의 테이블을 열의 일부만을 가지는 두 개 이상의 테이블로 분할하는 과정입니다. 모든 행은 유지되지만, 일부 열만 포함됩니다. primary key는 테이블마다 유지됩니다.
- 예시로, 사람들의 직업과 취미를 다루는 별도의 테이블을 생성할 수 있습니다.
- 테이블 병합(Table Merge)
- 두 개 이상의 테이블을 하나의 테이블로 결합하는 과정입니다. 이는 머신러닝 알고리즘 등을 적용하기 위해 단일 데이터셋 형태가 필요할 때 사용됩니다. (Machine learning 알고리즘은 오직 하나의 table만 가질 수 있음)
- 병합 과정에서는 테이블 간 공통된 열(예: 기본 키 또는 외래 키)을 기준으로 합니다.
Data Value Changes
- 데이터 전처리 과정에서 데이터의 값들을 변환하는 다양한 방법
- 데이터의 품질을 향상시키고, 분석이나 머신러닝 모델의 성능을 최적화하기 위해 필수적인 단계
- 종류
- Cleaning dirty data
- Text preprocessing
- Data discretization
- Data normalization/standardization
- Encoding for data mining algorithms
데이터 정제(Cleaning Dirty Data)
데이터에서 잘못된 정보(오류), 누락된 값, 사용할 수 없는 데이터, 이상치 등을 식별하고 수정하거나 제거하는 과정입니다. 이 과정은 데이터의 정확성과 신뢰성을 확보하는 데 중요합니다.
Missing Data
- Missing data의 두 가지 종류
- 진짜 값이 없는거 (income for a child)
- 의도적으로 입력하지 않은 값
- Missing data 다루는 방법
- 버리기
- 다른 값으로 치환하기
- Ignore Missing Data
- Ignore the feature (column) (vertical decomposition)
- Ignore the sample (row) (horizontal decomposition)
- Replace Missing Data
- Use attribute mean, median or mode based on similarity (same class, nearest neighbors, etc.)
- Using statistics and data mining algorithms (Computing the most probable value [k-nearest neighbors], clustering, sampling, regression, inference)
Wrong Data
- DBMS가 방지할 수 있는 잘못된 데이터
- 사용자가 데이터베이스 관리 시스템(DBMS)에서 데이터 무결성 제약 조건(예: 데이터 타입, 유니크 제약 조건, 프라이머리 키, 외래 키, 체크 제약 조건)을 적절히 설정하지 않아 발생하는 데이터 오류입니다.
- DBMS가 방지할 수 없는 잘못된 데이터
- 이는 더 복잡한 오류로, 데이터의 논리적 오류, 잘못된 데이터 입력, 시스템 간 데이터 통합 과정에서 발생하는 오류 등이 있습니다.
- Wrong Non-Primitive Data
- semi-structured data (e.g., email), and unstructured data (e.g., free-form text)
- compound data (e.g., point(x,y))
- time-series data
- categorical data (e.g., weather = sunny, rain, cloudy, snow,…)
- Many wrong data involving one entity
- 잘못된 입력
- 속성 값을 바꿔서 입력
- Many wrong data involving more than one entity
- 데이터베이스 내 두 테이블 간의 관계에서 일관성이 없거나, 데이터가 서로 모순되는 정보를 포함하는 경우
Unusable Data
- 데이터의 모호성
- 데이터가 분석 목적에 맞게 명확하게 정의되지 않았거나, 데이터의 의미가 분석 과정에서 다양하게 해석될 수 있는 경우입니다. 예를 들어, ‘광주’라는 데이터 포인트가 있는데, 이것이 대한민국의 광주광역시를 의미하는지, 아니면 중국의 광저우를 의미하는지 모호할 수 있습니다.
- 다양한 유효한 표현
- 동일한 정보가 데이터셋 내에서 다른 형태로 표현될 수 있습니다. 예를 들어, ‘Naver’와 ‘NHN Corp.’는 같은 회사를 지칭하지만 다르게 표현될 수 있습니다. 이러한 다양성은 데이터의 통합과 분석을 복잡하게 만듭니다.
- 표준에 부합하지 않는 데이터
- 데이터가 일반적으로 받아들여지는 표준이나 형식을 따르지 않는 경우입니다. 예를 들어, 날짜와 시간 데이터가 국가나 지역에 따라 다른 형식으로 기록되어 분석에 어려움을 주는 경우가 있습니다.
- 데이터베이스 통합 문제
- 서로 다른 데이터 소스나 시스템에서 통합된 데이터에서는 데이터 타입, 형식, 단위 등이 서로 다를 수 있으며, 이로 인해 데이터의 일관성 유지가 어려울 수 있습니다. 예를 들어, 한 시스템에서는 금액을 달러로 표시하는 반면 다른 시스템에서는 유로로 표시할 수 있습니다.
- 중복 데이터
- 데이터 통합 과정에서 동일한 정보가 여러 소스로부터 중복되어 들어올 수 있으며, 이는 데이터의 품질을 저하시키고 분석의 정확성을 떨어뜨릴 수 있습니다.
- 해결 방법
- 데이터베이스에 들어가기 전에 더러운 데이터 방지하기 (Prevention)
- 데이터 입력 단계에서의 검증: 데이터가 시스템에 입력될 때, 데이터의 형식, 무결성, 정확성 등을 검증하는 과정을 구현합니다. 이를 통해 잘못된 데이터가 데이터베이스에 저장되는 것을 사전에 방지할 수 있습니다.
- 무결성 제약 조건 설정: 데이터베이스 수준에서 데이터의 무결성을 보장하기 위한 제약 조건(예: 외래 키 제약 조건, 유니크 제약 조건 등)을 설정합니다. 이러한 제약 조건은 데이터의 일관성과 정확성을 유지하는 데 중요한 역할을 합니다.
- 트리거 사용: 데이터가 추가, 수정, 삭제될 때 자동으로 실행되는 트리거를 사용하여 데이터의 무결성을 유지할 수 있습니다. 예를 들어, 특정 조건을 만족하지 못하는 데이터가 입력되는 것을 방지할 수 있습니다.
- 데이터베이스에 들어간 후 더러운 데이터 정리하기 (Cleaning)
- 데이터 정제 도구 사용: 시장에는 다양한 상용 및 오픈 소스 데이터 정제 도구가 있습니다. 이 도구들을 사용하여 데이터의 오류를 식별하고 수정할 수 있습니다.
- 수동 정제: 때때로 자동화된 도구만으로는 모든 데이터 품질 문제를 해결할 수 없습니다. 이 경우, 데이터 전문가가 직접 데이터를 검토하고 수정하는 수동 정제 작업이 필요할 수 있습니다.
- 국가 또는 업계 표준 디렉토리 활용: 특정 유형의 데이터(예: 주소, 전화번호 등)에 대한 국가별 또는 업계별 표준 디렉토리를 활용하여 데이터의 정확성을 검증할 수 있습니다.
- 데이터베이스에 들어가기 전에 더러운 데이터 방지하기 (Prevention)
Outliers
- 이상치(Outliers)의 정의
- 이상치는 데이터 집합 내에서 다른 관측값들과 크게 다른 값을 가진 데이터 포인트를 의미합니다. 이상치는 측정 오류, 데이터 입력 실수, 또는 그 데이터 포인트가 실제로 특별한 경우를 나타내는 등 다양한 이유로 발생할 수 있습니다.
- 이상치의 영향
- 이상치는 평균, 표준편차와 같은 통계적 지표에 큰 영향을 줄 수 있으며, 결과적으로 데이터 분석이나 모델링 과정에서 왜곡된 결과를 초래할 수 있습니다. 따라서, 데이터를 분석하기 전에 이상치를 식별하고 적절하게 처리하는 것이 중요합니다.
- 이상치 처리 방법
- 제거: 이상치를 데이터 세트에서 완전히 제거하는 것이 한 방법입니다. 하지만 이 방법은 중요한 정보를 잃을 수 있다는 단점이 있습니다.
- 변환: 로그 변환과 같은 데이터 변환을 통해 이상치의 영향을 줄일 수 있습니다.
- 대체: 이상치를 다른 값으로 대체할 수 있습니다. 예를 들어, 평균값 또는 중앙값으로 대체하는 방법이 있습니다.
- 분리: 이상치를 별도의 그룹으로 분리하여 분석할 수 있습니다. 이 방법은 이상치가 가지고 있는 정보를 유지하면서도, 전체 데이터 분석에 미치는 영향을 최소화할 수 있습니다.
- 이상치 식별 방법
- 여러 가지 통계적 방법을 사용하여 이상치를 식별할 수 있습니다. Z-점수, IQR(Interquartile Range) 방법이 일반적으로 사용됩니다. 시각적 방법으로는 박스 플롯(Boxplot)이나 산점도(Scatter plot) 등을 사용하여 이상치를 식별할 수 있습니다.
텍스트 데이터 전처리(Text Data Processing)
텍스트 데이터를 분석 가능한 형태로 변환하기 위한 과정으로, 노이즈 제거, 토큰화, 정규화 등을 포함합니다. 이를 통해 텍스트 데이터에서 유용한 정보를 추출하고 분석의 정확도를 높일 수 있습니다. 데이터 과학과 머신 러닝은 숫자 데이터를 다루기 때문에, 텍스트를 숫자로 변환해줘야 한다.
Noise Removal
- 웹에서 말뭉치를 수집할 경우
- headers와 footers 텍스트 제거
- markup과 metadata 제거
Tokenization of Text Documents
- 토큰화는 긴 텍스트 문자열을 더 작고 관리하기 쉬운 조각들, 즉 ‘토큰’으로 나누는 과정을 말합니다. 이 과정은 텍스트 분석, 자연어 처리(NLP) 등에서 중요한 초기 단계입니다.
- 토큰화는 단어, 구, 문장 등의 경계를 식별하고, 텍스트 내에서의 단어 빈도수 분석, 문맥 분석, 감정 분석 등 다양한 텍스트 분석 작업의 기반이 됩니다.
- 토큰화 과정
- 단어 토큰화(Word Tokenization): 텍스트를 개별 단어로 분리하는 것입니다. 예를 들어, 문장 “OpenAI develops AI models”를 단어 ‘OpenAI’, ‘develops’, ‘AI’, ‘models’로 나눕니다.
- 문장 토큰화(Sentence Tokenization): 텍스트를 개별 문장으로 분리하는 것입니다. 특히, 문서나 긴 텍스트에서 각각의 문장을 독립적인 단위로 처리하기 위해 사용됩니다.
- 구 토큰화(Phrase Tokenization): 텍스트에서 의미 있는 구나 표현을 추출하는 과정입니다. 예를 들어, “New York City”를 하나의 토큰으로 처리할 수 있습니다.
- 토큰화의 도전 과제
- 구분자의 선택: 공백, 쉼표, 마침표 등 텍스트를 어떤 기준으로 나눌지 결정하는 것은 토큰화 과정에서 중요한 고려사항입니다.
- 문맥과 문법: 텍스트 내에서의 약어, 속어 등의 다양한 표현과 문맥에 따른 의미 변화를 적절히 처리하는 것이 필요합니다.
Normalization of Text Elements
- 텍스트 정규화는 텍스트 데이터를 일관된 형태로 변환하는 과정을 말하며, 이는 분석이나 자연어 처리(NLP) 작업의 정확도를 높이는 데 중요합니다.
- 정규화는 텍스트 데이터 내의 변이(variation)를 최소화하여, 동일한 의미를 가진 단어나 표현이 다양한 형태로 나타나는 것을 줄입니다. 이 과정을 통해 데이터 분석 및 모델링의 효율성과 정확도를 높일 수 있습니다.
- 단어의 대소문자 구분, 동의어 사용, 단어의 변형(예: 시제, 수, 활용 형태 등) 등은 같은 의미의 텍스트가 다르게 표현될 수 있음을 의미합니다. 이러한 차이를 줄임으로써, 텍스트 데이터의 일관성을 확보하고 분석을 용이하게 합니다.
- 주요 정규화 과정
- 소문자 변환: 모든 문자를 소문자로 변환하여 대소문자에 따른 변이를 제거합니다.
- 표제어 추출(Lemmatization): 단어를 그 기본형(사전형)으로 변환합니다. 예를 들어, “running”, “ran”, “runs”는 모두 “run”으로 변환됩니다.
- 어간 추출(Stemming): 단어에서 접미사를 제거하여 기본 어간을 추출합니다. 이는 더 빠르고 단순하지만, 때로는 정확도가 떨어질 수 있습니다.
- 불용어 제거(Stop Words Removal): “the”, “is”, “in”과 같이 의미 분석에 크게 기여하지 않는 단어를 제거합니다.
- 숫자, 특수 문자 제거: 분석 목적에 따라 숫자나 특수 문자를 제거할 수 있습니다.
- 텍스트 정제: 불필요한 공백, 특수 문자, 맞춤법 오류 등을 수정합니다.
데이터 이산화(Data Discretization)
- 이산화는 연속적인 값들을 명확한 구간으로 나누어 데이터의 복잡성을 줄이고, 분석을 용이하게 합니다
- 이산화 방법
- 동등 간격(Equidistant Binning): 전체 데이터 범위를 동일한 크기의 구간으로 나눕니다. 각 구간은 동일한 값을 가지는 데이터 포인트의 수와는 관계없이, 범위만을 기준으로 설정됩니다.
- 동일 빈도(Equal Frequency Binning): 각 구간에 동일한 수의 데이터 포인트가 오도록 데이터를 나눕니다. 이 방법은 데이터의 분포가 균등하지 않을 때 유용할 수 있습니다.
- 클러스터링(Clustering): 데이터 포인트 간의 유사성을 기반으로 클러스터를 형성하고, 이를 이용해 이산화를 수행합니다. K-평균 클러스터링이 이 방법에 자주 사용됩니다.
- 이산화의 도전 과제
- 구간 설정: 이산화 과정에서 가장 중요한 단계 중 하나는 구간의 수와 경계를 어떻게 설정할지 결정하는 것입니다. 적절한 구간 설정은 데이터의 특성을 잘 반영하고, 분석 목적에 맞게 데이터를 요약하는 데 중요합니다.
- 정보 손실: 연속형 데이터를 이산형으로 변환하는 과정에서 정보의 일부가 손실될 수 있습니다. 따라서, 이산화를 결정할 때는 정보 손실의 정도와 분석 목적 간의 균형을 고려해야 합니다.
데이터 정규화/표준화(Data Normalization/Standardization)
- 데이터의 스케일을 조정하여 다른 변수들과 비교 가능하게 만드는 과정입니다. 정규화는 데이터를 특정 범위(예: 0과 1 사이) 내로 조정하고, 표준화는 데이터를 평균이 0이고 표준편차가 1이 되도록 변환합니다.
- 이 과정은 특히 서로 다른 스케일을 가진 데이터를 다룰 때 중요하며, 많은 머신러닝 알고리즘에서 요구되는 전처리 단계입니다.
Min-Max Scaling
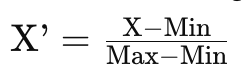
- 데이터를 정규화하는 한 방법으로, 데이터의 모든 값을 0과 1 사이의 범위로 조정합니다. 이 과정은 각 특성의 최소값을 0으로, 최대값을 1로 변환하여, 모든 데이터 포인트를 해당 범위 내로 스케일링합니다.
Z-Score (Standard) Scaling
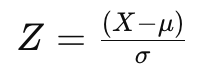
- 각 데이터 포인트에서 평균을 빼고 그 결과를 표준편차로 나누어 계산합니다. 이 과정은 데이터의 평균을 0으로, 표준편차를 1로 조정하여, 데이터의 분포를 표준 정규 분포와 유사하게 만듭니다.
Robust Scaling
- 데이터의 중앙값과 사분위수 범위(IQR: Interquartile Range)를 사용하여 스케일링하는 방법입니다. 이 방식은 이상치(outliers)의 영향을 받지 않는 스케일링 방법으로, 데이터가 이상치를 포함하고 있을 때 유용하게 사용됩니다.
Vector Normalizer (Direction Cosine)
- 벡터를 단위 벡터로 변환하는 방법을 설명합니다. 이 과정에서 각 벡터의 크기를 1로 조정하여, 벡터의 방향만을 유지합니다. 이 방식은 주로 벡터 간의 방향성 비교나 코사인 유사도 계산에 활용됩니다.
- 개념
- 단위 벡터: 길이(또는 크기)가 1인 벡터를 말하며, 원래 벡터의 방향은 유지하되 크기를 1로 조정합니다.
- 방향 코사인 (Direction Cosine): 단위 벡터로 변환된 벡터는 해당 벡터의 방향성을 나타내는 방향 코사인을 통해 표현됩니다. 방향 코사인은 원 벡터가 각 축과 이루는 각의 코사인 값으로, 벡터의 방향성을 나타내는데 사용됩니다.
Decimal Scaling
- 각 데이터 포인트를 10의 거듭제곱 수로 나누어 스케일을 조정합니다. 이 방식은 데이터의 절대 크기를 줄이면서도, 원래 데이터 값의 상대적인 크기 관계는 유지하게 됩니다.
- 방법
- 주어진 범위에서 가장 큰 수를 찾습니다
- 가장 큰 수의 자릿수를 세십시오 (예: j = 3)
- 각 숫자를 10j로 나눕니다 (예: 10^3 = 1000)
- -986부터 917까지의 정규화된 값은 -0.986부터 0.917입니다
Log Normalization
- 데이터의 범위를 줄이기 위해 로그 변환을 적용하는 방법입니다. 이 방법은 데이터의 분포가 극단적으로 치우친 경우(예: 한쪽으로 긴 꼬리를 가진 분포)나 이상치가 많은 데이터셋에 특히 유용합니다.
데이터 마이닝 알고리즘을 위한 인코딩(Encoding for Data Mining Algorithms)
- 비수치형 데이터를 수치형 데이터로 변환하는 과정입니다. 이는 대부분의 데이터 마이닝 알고리즘이 수치형 데이터를 입력으로 사용하기 때문에 필요합니다.
- 예를 들어, 범주형 변수의 레이블 인코딩이나 원-핫 인코딩이 이에 해당합니다.
- neural network 처리를 위해 데이터를 [0,1]이 되도록 변환합니다.
Choosing a Normalization Method
- 데이터 범위가 큰 경우: 로그 변환은 데이터의 범위가 매우 넓을 때(예: 4달러에서 1억 2천만 달러까지) 종종 좋은 선택입니다.
- 데이터가 치우친 경우: 대부분 데이터의 범위가 넓고 데이터가 치우친 경우에도 로그 변환은 효과적인 방법이 될 수 있습니다.
- 높은 엔트로피(매우 무작위적인 데이터)를 가진 데이터: 일반적으로 데이터를 -1에서 1 사이로 정규화하는 것이 좋습니다.
- 낮은 엔트로피(덜 무작위적인 데이터)를 가진 데이터: 이 경우에는 종종 Z-표준화(평균 0, 표준편차 1로 조정하는 방법)가 좋은 선택이 될 수 있습니다.
- 거의 정규 분포를 따르는 데이터: Z-표준화가 적합합니다.
Feature Engineering
용어
- Feature: 열
- Observation, sample: 행
Feature Engineering 종류
- Feature creation
- 목적에 맞는 관련된 feature를 얻고 만드는 과정
- Feature selection
- 주어진 dataset에서 가장 관련된 feature들을 선택하는 과정
- Feature reduction
- 데이터를 변형해서 feature의 갯수를 줄이는 과정
- 정보가 소수의 feature에 집중되도록
Feature Creation 종류
- 기존 특성에서 새로운 특성 유도
- 같은 entitiy 안의 기존 특성으로 새로운 특성 만들기
- 2개 이상의 다른 enitity의 특성을 합쳐서 새로운 특성 만들기
- 값을 특성으로 변경하기
Derive New Features from Existing Ones
- 용어 정리
- Entity (엔티티): 데이터베이스의 테이블이나 판다스(Pandas) 데이터 프레임과 같이 관련 데이터의 집합을 나타냅니다. 엔티티는 관측된 데이터 포인트들을 구성하며, 각 열(column)은 특성(feature)을, 각 행(row)은 관측치(observation)를 나타냅니다.
- Entity Set (엔티티 셋): 여러 엔티티들의 집합을 의미합니다. 엔티티 셋은 관련된 데이터를 그룹화하여 관리하고, 특성 생성 과정에서 다양한 엔티티 간의 관계를 정의하는 데 사용됩니다.
- Shared Variable (공유 변수): 두 엔티티 간의 관계를 정의하는 데 사용되는 변수로, 일반적으로 외래 키(foreign key)에 해당합니다. 공유 변수는 한 엔티티의 특성이 다른 엔티티의 특성과 연결되어 있음을 나타냅니다.
- Transformation (변환): 기존의 특성들로부터 새로운 특성을 유도하는 과정입니다. 변환은 같은 엔티티 내의 데이터를 사용하여 수행됩니다.
- Aggregation (집계): 서로 다른 엔티티들을 병합하거나, 엔티티 내의 그룹별로 통계를 계산하여 새로운 특성을 생성하는 과정입니다. 집계는 다른 엔티티의 정보를 요약하거나 통합하여 하나의 엔티티에 새로운 특성으로 추가합니다.
- Create a new feature by binning (categorizing) an existing feature
- 범주화를 통한 새로운 특성 생성:
- 행복도 점수 범주화: “행복” 수치 특성을 기반으로 “행복도 구간” 범주형 특성을 생성하는 것입니다. 예를 들어, 행복도 점수를 ‘낮음’, ‘중간’, ‘높음’의 세 구간으로 나눌 수 있습니다.
- 국가에서 지역으로의 범주화: “국가” 범주형 특성을 사용하여 “지역” 범주형 특성을 생성하는 것입니다. 예를 들어, 각 국가를 해당하는 대륙의 지역 이름으로 변환할 수 있습니다.
- 시간 및 날짜 특성 분리:
- 주어진 시간 및 날짜 특성을 “년”, “월”, “일”, “시”, “분”과 같은 여러 개의 새로운 특성으로 분리하여 분석에 더 많은 의미를 부여하는 것입니다.
- 수치형 특성의 변환:
- “가입일”과 “수입” 같은 시간-날짜 특성과 수치형 특성에서 “가입 월”과 “로그 수입” 같은 새로운 특성을 생성하는 것입니다. 이를 통해 모델이 데이터의 계절성을 파악하거나, 수입 데이터의 분포를 균일하게 만들어 분석 효율을 높일 수 있습니다.
- 범주화를 통한 새로운 특성 생성:
- Merging or Aggregating Over Different Entities
- 머신 러닝 알고리즘은 단일 엔티티(테이블)의 데이터만을 입력으로 사용할 수 있습니다. 따라서 논리적으로 연결된 여러 엔티티(예: 고객, 대출, 지불 내역 등)의 데이터를 모델링에 활용하기 위해서는 이들을 하나의 엔티티로 통합해야 합니다.
Converting Values to New Features
- 기존 데이터 값을 새로운 형태의 특성으로 변환하여 머신 러닝 모델이 더 잘 이해할 수 있도록 만드는 작업을 말합니다. 이러한 변환은 특히 범주형 데이터, 텍스트 데이터, 이미지 데이터를 다룰 때 필수적입니다.
- 범주형 데이터 값을 특성으로 변환:
- One-Hot Encoding: 범주형 변수가 갖는 여러 카테고리 값을 이진 특성의 형태로 변환하는 방법입니다. 예를 들어, ‘날씨’ 변수가 ‘맑음’, ‘흐림’, ‘비’, ‘눈’의 네 가지 값을 가진다면, 이를 네 개의 이진 특성(맑음=1, 나머지=0 등)으로 변환합니다. 이 방법은 머신 러닝 모델이 범주형 데이터를 수치적으로 처리할 수 있게 해줍니다.
- 텍스트 데이터를 벡터로 변환:
- 텍스트 데이터 처리에 있어서, 각 단어나 문장을 고정된 크기의 숫자 벡터로 변환하는 것이 일반적입니다. 예를 들어, One-Hot Encoding을 사용하여 코퍼스 내의 각 단어를 해당 단어를 나타내는 인덱스 위치에만 1이고 나머지는 0인 벡터로 변환할 수 있습니다. 이는 텍스트 데이터를 머신 러닝 알고리즘이 처리할 수 있는 형태로 만들어줍니다.
- 예시: “cat”, “dog”, “bird” 세 단어로 구성된 코퍼스가 있다고 가정할 때, “cat”에 [1, 0, 0], “dog”에 [0, 1, 0], “bird”에 [0, 0, 1]과 같은 벡터를 할당합니다.
- 이미지 픽셀을 특성으로 변환:
- 이미지 데이터를 처리할 때, 각 이미지를 구성하는 픽셀 값을 독립적인 특성으로 변환하여 사용합니다. 예를 들어, 28×28 크기의 이미지는 784개의 특성으로 변환됩니다. 각 픽셀의 밝기 또는 색상 값은 해당 특성의 값으로 사용됩니다. 이 방법은 이미지를 숫자 데이터의 집합으로 변환하여 컴퓨터가 이미지를 ‘이해’하고 분석할 수 있게 해줍니다.
- 이미지 표현 방법 종류
- Bitmap graphic method
- 이미지를 픽셀로 나눔
- Vector graphics
- 수학적인 공식으로 표현하고 저장함 (곡선과 선의 조합)
- Bitmap graphic method
Feature Selection
- 데이터 세트 내의 특성(변수) 중에서 모델의 성능에 실제로 기여하는 중요한 특성을 선택하고, 관련성이 낮거나 불필요한 특성을 제거합니다. 이를 통해 모델의 효율성을 높이고, 과적합(overfitting)을 방지하며, 모델의 해석력을 향상시키는 데 목적이 있습니다.
- Feature Selection 방법
- Filter Methods (필터 방법):
- 데이터의 통계적 속성을 기반으로 특성을 평가하고 선택합니다.
- 모델의 학습 과정 이전에 수행되며, 상관 계수, 카이제곱 검정, 정보 이득 등을 사용할 수 있습니다.
- 계산 비용이 낮고, 빠르게 수행됩니다.
- Wrapper Methods (래퍼 방법):
- 특정 머신 러닝 알고리즘의 성능을 기준으로 특성의 중요성을 평가합니다.
- 순차적 특성 선택(Sequential Feature Selection), 재귀적 특성 제거(Recursive Feature Elimination, RFE) 등이 있습니다.
- 계산 비용이 높지만, 선택된 특성이 특정 모델에 최적화됩니다.
- Embedded Methods (임베디드 방법):
- 모델 자체의 학습 과정 중에 특성 선택이 이루어집니다.
- 정규화(Regularization) 방법을 사용하는 모델들(Lasso, Ridge, Elastic Net 등)이 이에 해당합니다.
- 모델 학습과 특성 선택을 동시에 수행하여 효율적입니다.
- Filter Methods (필터 방법):